Autograd Functions¶
Overview¶
pyepo.func provides PyTorch autograd modules that wrap an optimization solver and supply informative gradients for end-to-end training. All modules assume a linear objective with known, fixed constraints; the cost vector is predicted from contextual features.
The modules fall into two interfaces:
Loss-returning modules produce a scalar loss and feed straight into
.backward().Solution-returning modules produce predicted, expected, or regularized solutions; the user defines a task loss on top.
For training-loop templates, see Training.
Choosing a Method¶
Strong defaults (when in doubt)
When \(\mathbf{w}^*\) labels are available, start with SPO+: convex, has a nonzero subgradient, and is well-studied as a baseline.
When the loss-returning style is preferred and labels include \(\mathbf{w}^*\), PFYL avoids the extra task loss.
For binary linear programs (TSP, CVRP, knapsack, shortest path with binary edges), use CaVE: a cone-alignment loss whose projection (an interior-point QP via Clarabel) replaces the per-step ILP solve, with paper-faithful regret on TSP-scale binary LPs. Because the cone projection is far cheaper than the per-instance ILP solve, CaVE trains an order of magnitude faster than SPO+ at this scale.
For very large LPs on GPU, combine MPAX models with SPO+ or PFYL.
For finer choices, the right method depends on three questions.
1. What supervision do you have at training time?
True optimal solutions \(\mathbf{w}^*\) — SPO+, PFYL, RFYL, DPO+MSE, RFWO+MSE, I-MLE+L1, AI-MLE+L1, NCE, CMAP
Just true costs \(\mathbf{c}\) — PG, LTR variants
True optimal objective values \(z^*\) — DBB+L1, NID+L1 (objective-value loss)
Binding constraints at the optimum — CaVE (binary linear programs only)
2. Should the module return a loss or a solution?
A loss (use directly in
.backward()) — SPO+, PFYL, RFYL, NCE, CMAP, LTR, PG, CaVEA solution (define your own task loss) — DPO, DBB, NID, RFWO, I-MLE, AI-MLE
3. Any special constraints?
Sign-sensitive oracle (e.g., negative costs must stay negative) — use
perturbedOptMulorperturbedFenchelYoungMulwith a positive-output predictor.Large LP on GPU — pair an
optMpaxModelwith SPO+ or PFYL.Cached negative pool — NCE / CMAP.
Ranking interpretation — LTR variants.
The table below summarizes inputs and return types.
Module |
Returns |
Typical supervision |
Notes |
|---|---|---|---|
|
loss |
true costs, true optimal solutions, true objective values |
strong default for linear objectives |
|
loss |
true costs |
directional finite differences along the true cost |
|
expected perturbed solutions |
task loss chosen by the user |
DPO; use the multiplicative variant for sign-sensitive oracles |
|
loss |
true optimal solutions |
PFYL; use the multiplicative variant for sign-sensitive oracles |
|
perturbed solutions |
task loss chosen by the user |
perturb-and-MAP with Sum-of-Gamma noise |
|
regularized predicted solutions |
task loss chosen by the user |
L2-regularized smooth optimizer over the convex hull of feasible solutions |
|
loss |
true optimal solutions |
Fenchel-Young loss paired with L2-regularized Frank-Wolfe |
|
predicted solutions |
task loss chosen by the user |
direct solution-level or objective-level losses |
|
loss |
tight binding-constraint normals at the true optimum ( |
CaVE; binary linear programs only |
|
loss |
true optimal solutions and a solution pool |
contrastive training with cached negative solutions |
|
loss |
true costs and a solution pool |
learning-to-rank formulations over feasible solutions |
Surrogate Losses¶
Surrogate losses replace the non-differentiable regret with a smooth surrogate that has informative gradients.
Smart Predict-then-Optimize+ Loss (SPO+)¶
SPO+ [1] is a convex surrogate loss for the SPO Loss (regret), which measures the decision error of an optimization problem.
The derivation starts from the observation that for any \(\alpha \geq 0\),
Setting \(\alpha = 2\) and bounding \(z^*(2 \hat{\mathbf{c}}) \leq 2 \hat{\mathbf{c}}^\top \mathbf{w}^*(\mathbf{c})\) via the concavity of \(z^*\) gives the SPO+ loss,
which is convex in \(\hat{\mathbf{c}}\) and upper-bounds the regret. By Danskin’s theorem, an informative subgradient is
- class pyepo.func.SPOPlus(optmodel: optModel, processes: int = 1, solve_ratio: float = 1.0, reduction: Reduction = 'mean', dataset: optDataset | None = None)
SPO+ loss: a convex surrogate for the SPO regret of a linear-objective LP.
SPO+ upper-bounds the SPO regret with a convex function of the predicted cost vector and provides an informative subgradient (via Danskin’s theorem) for end-to-end training. It is the strong default for predict-then-optimize when true optimal solutions \(\mathbf{w}^*(\mathbf{c})\) are available as supervision.
The forward pass solves the perturbed problem with cost \(2\hat{\mathbf{c}} - \mathbf{c}\) once per training instance and returns a scalar loss; the backward pass uses the cached solution to form the subgradient \(2(\mathbf{w}^*(\mathbf{c}) - \mathbf{w}^*(2\hat{\mathbf{c}} - \mathbf{c}))\) without any extra solver call.
Reference: Elmachtoub & Grigas (2022) https://doi.org/10.1287/mnsc.2020.3922
processes sets the number of solver processes (0 uses all available cores).
Perturbation Gradient (PG)¶
PG [10] is a surrogate loss based on zeroth-order gradient approximation via Danskin’s theorem. It uses finite differences along the true cost direction to estimate informative gradients through the optimization solver.
By Danskin’s theorem, regret can be written as the directional derivative of \(z^*(\hat{\mathbf{c}})\) along \(\mathbf{c}\) (up to a constant independent of \(\hat{\mathbf{c}}\)). PG approximates this directional derivative with finite differences. Two variants are available — backward (two_sides=False) and central (two_sides=True):
where \(\lambda > 0\) is the finite-difference width (the sigma parameter). The corresponding gradients fall out directly from the perturbed solutions, e.g.
- class pyepo.func.perturbationGradient(optmodel: optModel, sigma: float = 0.1, two_sides: bool = False, processes: int = 1, solve_ratio: float = 1.0, reduction: Reduction = 'mean', dataset: optDataset | None = None)
Perturbation Gradient (PG): zeroth-order surrogate of the objective-value loss.
PG approximates the directional derivative of \(z^*(\hat{\mathbf{c}})\) along the true cost \(\mathbf{c}\) with a finite difference, yielding an informative gradient through the otherwise piecewise-constant solver layer. Two variants are exposed via
two_sides: backward differencing (False, one extra solve per step) and central differencing (True, two extra solves but more accurate gradients).Unlike SPO+, PG does not require true optimal solutions – it only needs the true cost vector \(\mathbf{c}\).
Reference: Gupta & Huang (2024) https://arxiv.org/abs/2402.03256
sigma controls the finite-difference width. two_sides enables central differencing for more accurate gradient estimates.
Perturbed Methods¶
Perturbed methods estimate gradients by Monte Carlo averaging over random perturbations of the cost vector. They share two design knobs: n_samples (number of Monte Carlo samples) and sigma (perturbation amplitude).
Differentiable Perturbed Optimizer (DPO)¶
DPO [4] uses Monte Carlo sampling to estimate solutions by optimizing randomly perturbed costs. Its custom backward pass provides a gradient estimator for end-to-end training. perturbedOpt is the additive Gaussian version; perturbedOptMul is the multiplicative version for sign-sensitive oracles [5]. The multiplicative variant assumes predicted costs already have the intended nonzero sign — for nonnegative-cost problems, use a positive-output predictor such as nn.Softplus() plus a small epsilon.
DPO replaces the piecewise-constant solution map \(\hat{\mathbf{c}} \mapsto \mathbf{w}^*(\hat{\mathbf{c}})\) with the expectation over a random perturbation,
where \(\boldsymbol{\xi} \sim \mathcal{N}(\mathbf{0}, \mathbf{I})\) and \(K\) is n_samples. The expectation varies smoothly with \(\hat{\mathbf{c}}\) because small perturbations only shift the sampling distribution over active vertices of the feasible polytope — analogous to the smoothing role of SoftMax in classification.
The multiplicative variant perturbedOptMul perturbs each entry of \(\hat{\mathbf{c}}\) as
with \(\odot\) the Hadamard product. The exponential factor preserves the sign of each cost entry, which is required when the solver expects (say) nonnegative edge costs.
- class pyepo.func.perturbedOpt(optmodel: optModel, n_samples: int = 10, sigma: float = 1.0, processes: int = 1, seed: int = 135, variance_reduction: bool = True, solve_ratio: float = 1.0, dataset: optDataset | None = None)
Differentiable Perturbed Optimizer (DPO) – additive-Gaussian variant.
Estimates the expected solution \(\mathbb{E}_{\boldsymbol{\xi}}[\mathbf{w}^*(\hat{\mathbf{c}} + \sigma\boldsymbol{\xi})]\) by Monte Carlo averaging over
n_samplesGaussian perturbations of the predicted cost vector. The smoothed map varies continuously with \(\hat{\mathbf{c}}\) – small perturbations only re-weight the distribution over active vertices – giving an informative gradient where the bare LP solver gives zero.Returns a solution, not a loss: the user supplies a task loss (MSE against \(\mathbf{w}^*(\mathbf{c})\) is the standard choice). For sign-sensitive oracles, use
perturbedOptMulinstead.Reference: Berthet et al. (2020) https://papers.nips.cc/paper/2020/hash/6bb56208f672af0dd65451f869fedfd9-Abstract.html
- class pyepo.func.perturbedOptMul(optmodel: optModel, n_samples: int = 10, sigma: float = 1.0, processes: int = 1, seed: int = 135, variance_reduction: bool = True, solve_ratio: float = 1.0, dataset: optDataset | None = None)
Multiplicative-perturbation variant of
perturbedOptfor sign-sensitive oracles.Replaces additive noise with the multiplicative perturbation \(\hat{\mathbf{c}} \odot \exp(\sigma\boldsymbol{\xi} - \tfrac{1}{2}\sigma^2)\), which preserves the sign of each cost entry – required when the solver expects, e.g., strictly nonnegative edge costs. Predicted costs must already carry the intended nonzero sign; for nonnegative problems pair this module with a positive-output prediction layer (e.g.
nn.Softplus()plus a small epsilon).Reference: Dalle et al. (2022) https://arxiv.org/abs/2207.13513
Perturbed Fenchel-Young Loss (PFYL)¶
PFYL [4] uses the same perturbed expected solution as DPO inside a Fenchel-Young loss, comparing it directly with the true optimal solution. It returns a loss, so no external task loss is needed. perturbedFenchelYoung is the additive Gaussian version; perturbedFenchelYoungMul is the multiplicative sign-preserving variant with the same sign convention as perturbedOptMul.
Let \(F(\hat{\mathbf{c}}) = \mathbb{E}_{\boldsymbol{\xi}}\big[ \min_{\mathbf{w} \in \mathcal{S}} (\hat{\mathbf{c}} + \sigma \boldsymbol{\xi})^\top \mathbf{w} \big]\) be the expected perturbed minimum, and let \(\Omega(\mathbf{w}^*(\mathbf{c}))\) be its Fenchel conjugate. The perturbed Fenchel-Young loss is
The dual term \(\Omega(\mathbf{w}^*(\mathbf{c}))\) does not depend on \(\hat{\mathbf{c}}\), so the gradient collapses to a simple difference of solutions,
Compared with DPO, PFYL avoids an explicit Jacobian computation and yields a theoretically grounded loss tied to the duality gap. The multiplicative variant uses the same sign-preserving perturbation,
- class pyepo.func.perturbedFenchelYoung(optmodel: optModel, n_samples: int = 10, sigma: float = 1.0, processes: int = 1, seed: int = 135, solve_ratio: float = 1.0, reduction: Reduction = 'mean', dataset: optDataset | None = None)
Perturbed Fenchel-Young loss (PFYL) – additive-Gaussian variant.
Pairs the same Monte-Carlo expected perturbed solution as
perturbedOptwith the Fenchel-Young loss against the true optimum \(\mathbf{w}^*(\mathbf{c})\), returning a scalar loss directly – no user-defined task loss needed. The gradient collapses to the simple residual \(\mathbf{w}^*(\mathbf{c}) - \mathbb{E}_{\boldsymbol{\xi}} [\mathbf{w}^*(\hat{\mathbf{c}} + \sigma\boldsymbol{\xi})]\), so no explicit Jacobian through the solver is required. For sign-sensitive oracles, useperturbedFenchelYoungMul.Reference: Berthet et al. (2020) https://papers.nips.cc/paper/2020/hash/6bb56208f672af0dd65451f869fedfd9-Abstract.html
- class pyepo.func.perturbedFenchelYoungMul(optmodel: optModel, n_samples: int = 10, sigma: float = 1.0, processes: int = 1, seed: int = 135, solve_ratio: float = 1.0, reduction: Reduction = 'mean', dataset: optDataset | None = None)
Multiplicative-perturbation variant of
perturbedFenchelYoungfor sign-sensitive oracles.Uses the same sign-preserving multiplicative perturbation \(\hat{\mathbf{c}} \odot \exp(\sigma\boldsymbol{\xi} - \tfrac{1}{2}\sigma^2)\) as
perturbedOptMul. Predicted costs must carry the intended nonzero sign; for nonnegative problems pair this module with a positive-output prediction layer (e.g.nn.Softplus()plus a small epsilon).Reference: Dalle et al. (2022) https://arxiv.org/abs/2207.13513
Implicit Maximum Likelihood Estimator (I-MLE)¶
I-MLE [8] uses the perturb-and-MAP framework, sampling noise from a Sum-of-Gamma distribution and interpolating the loss function to approximate finite differences. lambd controls the interpolation step.
I-MLE is framed as imitation learning: bring the model distribution \(p(\mathbf{w} \mid \hat{\mathbf{c}})\) closer to a target distribution \(q(\mathbf{w} \mid \hat{\mathbf{c}})\) by minimizing their KL divergence. An upstream task gradient \(\mathbf{d} = \nabla_{\mathbf{w}} \mathcal{L}(\hat{\mathbf{c}}, \cdot) \big|_{\mathbf{w} = \mathbf{w}^*(\hat{\mathbf{c}})}\) induces a virtual update \(\hat{\mathbf{c}}' = \hat{\mathbf{c}} + \lambda \mathbf{d}\), and the gradient is estimated by a directional finite difference between the smoothed solutions at \(\hat{\mathbf{c}}'\) and \(\hat{\mathbf{c}}\):
where \(\sigma\) smooths the solution map and \(\lambda\) (lambd) is the finite-difference step. The same noise realization \(\boldsymbol{\xi}_\kappa\) is shared across the two perturbed evaluations to reduce variance.
- class pyepo.func.implicitMLE(optmodel: optModel, n_samples: int = 10, sigma: float = 1.0, lambd: float = 10, distribution: sumGammaDistribution | None = None, two_sides: bool = False, processes: int = 1, solve_ratio: float = 1.0, dataset: optDataset | None = None)
Implicit Maximum Likelihood Estimator (I-MLE) via perturb-and-MAP.
Frames decision-focused learning as imitation: an upstream task gradient \(\mathbf{d}\) induces a virtual update \(\hat{\mathbf{c}}' = \hat{\mathbf{c}} + \lambda \mathbf{d}\), and the gradient is estimated by a directional finite difference between smoothed solutions at \(\hat{\mathbf{c}}'\) and \(\hat{\mathbf{c}}\), sharing the same Sum-of-Gamma noise realization across the two evaluations to reduce variance.
Returns the (perturbation-smoothed) predicted solution; the user supplies a task loss (L1 against \(\mathbf{w}^*(\mathbf{c})\) is standard).
Reference: Niepert, Minervini & Franceschi (2021) https://proceedings.neurips.cc/paper_files/paper/2021/hash/7a430339c10c642c4b2251756fd1b484-Abstract.html
Adaptive Implicit Maximum Likelihood Estimator (AI-MLE)¶
AI-MLE [9] extends I-MLE with an adaptive interpolation step for better gradient estimates.
AI-MLE uses the same finite-difference estimator as I-MLE but replaces the fixed step size \(\lambda\) with an adaptive choice driven by the magnitudes of the predicted cost and the upstream gradient,
where \(\mathbf{d}\) is the upstream task gradient and \(\alpha_t > 0\) is tuned online: when an exponential moving average of the gradient sparsity (fraction of nonzero entries) drops below one, \(\alpha_t\) is increased; otherwise it is decreased. This rescaling keeps the perturbation magnitude commensurate with \(\hat{\mathbf{c}}\) and decouples the step from the absolute scale of \(\mathbf{d}\), removing the need to tune \(\lambda\) by hand.
- class pyepo.func.adaptiveImplicitMLE(optmodel: optModel, n_samples: int = 10, sigma: float = 1.0, distribution: sumGammaDistribution | None = None, two_sides: bool = False, processes: int = 1, solve_ratio: float = 1.0, dataset: optDataset | None = None)
Adaptive Implicit MLE (AI-MLE): I-MLE with an adaptive interpolation step.
Replaces I-MLE’s fixed finite-difference step \(\lambda\) with the data-dependent choice \(\lambda_t = \alpha_t \cdot \|\hat{\mathbf{c}}\| / \|\mathbf{d}\|\), where the magnitude \(\alpha_t\) is tuned online from a moving average of gradient sparsity. The rescaling keeps the perturbation commensurate with \(\hat{\mathbf{c}}\) and removes the need to tune \(\lambda\) by hand, while the rest of the forward / backward path is identical to
implicitMLE.Reference: Minervini, Franceschi & Niepert (2023) https://ojs.aaai.org/index.php/AAAI/article/view/26103
Regularized Methods¶
A pure linear optimization layer is not differentiable: the optimal solution \(\mathbf{w}^*(\hat{\mathbf{c}}) = \arg\min_{\mathbf{w} \in \mathcal{S}} \hat{\mathbf{c}}^\top \mathbf{w}\) is piecewise constant in \(\hat{\mathbf{c}}\) — it jumps between vertices of \(\mathcal{S}\) and its derivative is zero almost everywhere. Regularized methods fix this by adding a strongly convex regularizer \(\Omega\) to the linear objective, yielding a regularized solution
which is unique, lies inside \(\mathrm{conv}(\mathcal{S})\), and varies continuously with \(\hat{\mathbf{c}}\). This deterministic smoothing is dual to the stochastic smoothing of the perturbed methods above: both replace the piecewise-constant solution map with a continuous surrogate, the former via a convex regularizer and the latter via Monte Carlo averaging over a noise distribution [5].
PyEPO implements the L2 special case \(\Omega(\mathbf{w}) = \tfrac{\lambda}{2} \|\mathbf{w}\|_2^2\) and solves the regularized program with batched Frank-Wolfe iteration. Frank-Wolfe is the natural choice here: it accesses \(\mathrm{conv}(\mathcal{S})\) only through the original LP/ILP solver of \(\mathcal{S}\) (a linear minimization oracle), so no explicit polytope representation is needed — the same Gurobi/COPT/OR-Tools/MPAX backend used elsewhere in PyEPO supplies the LMO. lambd is the L2 strength \(\lambda\); max_iter caps Frank-Wolfe iterations and tol is the convergence tolerance.
L2 Regularized Frank-Wolfe (RFWO)¶
RFWO [5] exposes \(\hat{\mathbf{w}}_\lambda(\hat{\mathbf{c}})\) directly as a differentiable layer. Since it returns a (regularized) solution rather than a loss, the user defines a task loss on the output — most commonly an MSE against \(\mathbf{w}^*(\mathbf{c})\), matching the imitation setting in the original paper.
- class pyepo.func.regularizedFrankWolfeOpt(optmodel: optModel, lambd: float = 1.0, max_iter: int = 20, tol: float = 1e-06, processes: int = 1, solve_ratio: float = 1.0, dataset: optDataset | None = None)
L2-Regularized Frank-Wolfe Optimizer (RFWO) – differentiable smoothed solver.
Adds an L2 regularizer \(\tfrac{\lambda}{2}\|\mathbf{w}\|_2^2\) to the linear objective and returns the regularized minimizer \(\hat{\mathbf{w}}_\lambda(\hat{\mathbf{c}}) = \arg\min_{\mathbf{w} \in \mathrm{conv}(\mathcal{S})} \hat{\mathbf{c}}^\top \mathbf{w} + \tfrac{\lambda}{2}\|\mathbf{w}\|_2^2\), which is unique, lies inside \(\mathrm{conv}(\mathcal{S})\), and varies continuously with \(\hat{\mathbf{c}}\). The program is solved by batched Frank-Wolfe iteration; the only oracle needed is the underlying linear solver (PyEPO’s standard
optModel.solve).Returns a regularized solution – not a loss. Pair with a user-defined task loss (MSE against \(\mathbf{w}^*(\mathbf{c})\) matches the imitation setting in the paper), or use
regularizedFrankWolfeFenchelYoungfor the loss-returning variant.Reference: Dalle et al. (2022) https://arxiv.org/abs/2207.13513
L2 Regularized Frank-Wolfe with Fenchel-Young Loss (RFYL)¶
RFYL [5] pairs the RFWO layer with the Fenchel-Young loss [12] of the regularizer \(\Omega\), returning a scalar loss that compares the predicted cost \(\hat{\mathbf{c}}\) to the true optimum \(\mathbf{w}^*(\mathbf{c})\) directly — no external task loss needed.
For any convex regularizer \(\Omega: \mathrm{conv}(\mathcal{S}) \to \mathbb{R}\) with conjugate \(\Omega^*(\boldsymbol{\theta}) = \sup_{\mathbf{w}} \boldsymbol{\theta}^\top \mathbf{w} - \Omega(\mathbf{w})\), the Fenchel-Young loss is
The Fenchel-Young inequality guarantees three properties that make it ideal for end-to-end training:
Non-negative, with equality iff \(\mathbf{w}^*(\mathbf{c}) = \hat{\mathbf{w}}_\Omega(\hat{\mathbf{c}})\).
Convex in \(\hat{\mathbf{c}}\).
By Danskin’s theorem, the gradient is the residual between the regularized prediction and the target,
\[\frac{\partial \mathcal{L}_\Omega^{\mathrm{FY}}(\hat{\mathbf{c}}, \mathbf{w}^*(\mathbf{c}))}{\partial \hat{\mathbf{c}}} = \mathbf{w}^*(\mathbf{c}) - \hat{\mathbf{w}}_\Omega(\hat{\mathbf{c}}),\]so no implicit differentiation through the Frank-Wolfe iterate is needed.
PyEPO specializes this to \(\Omega(\mathbf{w}) = \tfrac{\lambda}{2}\|\mathbf{w}\|_2^2\). Substituting the closed form of \(\Omega^*\) and the definition of \(\hat{\mathbf{w}}_\lambda\) collapses the loss to
a transparent “compare regularizers + linear residual” form. The gradient remains \(\mathbf{w}^*(\mathbf{c}) - \hat{\mathbf{w}}_\lambda(\hat{\mathbf{c}})\).
- class pyepo.func.regularizedFrankWolfeFenchelYoung(optmodel: optModel, lambd: float = 1.0, max_iter: int = 20, tol: float = 1e-06, processes: int = 1, solve_ratio: float = 1.0, reduction: Reduction = 'mean', dataset: optDataset | None = None)
L2-Regularized Frank-Wolfe with Fenchel-Young loss (RFYL).
Pairs the RFWO regularized solver with the Fenchel-Young loss of the L2 regularizer, returning a convex scalar loss that compares the predicted cost \(\hat{\mathbf{c}}\) to the true optimum \(\mathbf{w}^*(\mathbf{c})\) directly – no user-defined task loss needed. Specialized to \(\Omega(\mathbf{w}) = \tfrac{\lambda}{2}\|\mathbf{w}\|_2^2\), the loss collapses to a transparent “compare regularizers + linear residual” form.
By Danskin’s theorem the gradient is the simple residual \(\mathbf{w}^*(\mathbf{c}) - \hat{\mathbf{w}}_\lambda (\hat{\mathbf{c}})\), so the backward path skips implicit differentiation through the Frank-Wolfe iterate.
Reference: Dalle et al. (2022) https://arxiv.org/abs/2207.13513
Black-Box Methods¶
Black-box methods substitute informative gradient estimates for the zero gradient of the discrete solver.
Differentiable Black-Box Optimizer (DBB)¶
DBB [2] estimates gradients via interpolation, replacing the zero gradients of the combinatorial solver. lambd is a smoothing hyperparameter (recommended range: 10 to 20).
Given an upstream gradient \(\mathbf{d} = \nabla_{\mathbf{w}} \mathcal{L}(\hat{\mathbf{c}}, \cdot) \big|_{\mathbf{w} = \mathbf{w}^*(\hat{\mathbf{c}})}\), DBB approximates the vector-Jacobian product by interpolating the loss between \(\hat{\mathbf{c}}\) and a perturbed cost \(\hat{\mathbf{c}} + \lambda \mathbf{d}\), yielding
Larger \(\lambda\) smooths more aggressively. Unlike SPO+, the resulting surrogate is nonconvex in \(\hat{\mathbf{c}}\), which weakens convergence guarantees even when the predictor is convex in its parameters.
- class pyepo.func.blackboxOpt(optmodel: optModel, lambd: float = 10, processes: int = 1, solve_ratio: float = 1.0, dataset: optDataset | None = None)
Differentiable Black-Box Optimizer (DBB) – gradient via solution interpolation.
Replaces the zero gradient of the combinatorial solver with an interpolation-based estimate: given an upstream gradient \(\mathbf{d}\), DBB approximates the vector-Jacobian product as \((\mathbf{w}^*(\hat{\mathbf{c}} + \lambda \mathbf{d}) - \mathbf{w}^*(\hat{\mathbf{c}})) / \lambda\). Larger
lambdsmooths more aggressively; the recommended range is 10-20. The resulting surrogate is nonconvex in \(\hat{\mathbf{c}}\), so convergence guarantees are weaker than SPO+.Returns a predicted solution – pair with an objective-value task loss such as L1 against \(z^*(\mathbf{c})\).
Reference: Vlastelica et al. (2019) https://arxiv.org/abs/1912.02175
- forward(pred_cost: torch.Tensor) torch.Tensor
Forward pass
Negative Identity Backpropagation (NID)¶
NID [3] treats the solver as a negative identity mapping during backpropagation. This is equivalent to DBB with a specific hyperparameter setting. NID is hyperparameter-free and requires no additional solver calls during the backward pass.
NID approximates the solver Jacobian by the (signed) identity, \(\partial \mathbf{w}^*(\hat{\mathbf{c}}) / \partial \hat{\mathbf{c}} \approx -\mathbf{I}\) for a minimization problem (and \(+\mathbf{I}\) for maximization). Given an upstream gradient \(\mathbf{d} = \partial \mathcal{L}(\hat{\mathbf{c}}, \cdot) / \partial \mathbf{w}^*(\hat{\mathbf{c}})\), the chain rule gives a sign-flipped straight-through estimator,
Intuitively, for minimization this rule decreases \(\hat{\mathbf{c}}\) along directions where \(\mathbf{w}^*(\hat{\mathbf{c}})\) tends to increase and vice versa, driving the predicted decision toward \(\mathbf{w}^*(\mathbf{c})\). NID is the special case of DBB in which \(\lambda\) is chosen so that the interpolated solution coincides with the negative-identity update — but it saves the extra solver call required by DBB.
- class pyepo.func.negativeIdentity(optmodel: optModel, processes: int = 1, solve_ratio: float = 1.0, dataset: optDataset | None = None)
Negative Identity Backpropagation (NID) – hyperparameter-free DBB.
Treats the solver Jacobian as a (signed) identity: \(\partial \mathbf{w}^* / \partial \hat{\mathbf{c}} \approx -\mathbf{I}\) for minimization (and \(+\mathbf{I}\) for maximization), yielding a straight-through gradient estimator. This is the special case of DBB where \(\lambda\) is chosen so the interpolated solution coincides with the negative-identity update – with the bonus that no extra solver call is needed on the backward pass.
Returns a predicted solution; pair with an objective-value task loss (e.g., L1 against \(z^*(\mathbf{c})\)).
Reference: Sahoo et al. (2022) https://arxiv.org/abs/2205.15213
- forward(pred_cost: torch.Tensor) torch.Tensor
Forward pass
Cone-Aligned Estimation¶
Cone-aligned losses supervise the predicted cost vector directly by aligning it with the polyhedral cone of binding-constraint normals at the true optimum, rather than supervising on the optimal solution itself.
Cone-Aligned Vector Estimation (CaVE)¶
CaVE [11] is a surrogate loss for binary linear programs (TSP, CVRP, knapsack, shortest path with binary edges, etc.). For each instance, it projects the sense-flipped predicted cost vector onto the polyhedral cone spanned by the binding-constraint normals at the true optimal vertex, then minimizes 1 - cos(pred, proj). Because the supervision is the cone of binding-constraint normals at the optimum — not the optimal solution itself — CaVE side-steps the zero-gradient pathology of solver layers without requiring a Monte Carlo perturbation or a solution pool.
For a runnable walkthrough that compares CaVE against SPO+ on TSP, see the 04 CaVE for Binary Linear Programs notebook.
Let \(K(\mathbf{w}^*(\mathbf{c}))\) be the polyhedral cone spanned by the constraint normals that bind at the true optimal vertex. For a minimization problem, the KKT conditions require \(-\hat{\mathbf{c}} \in K(\mathbf{w}^*(\mathbf{c}))\) for \(\mathbf{w}^*(\mathbf{c})\) to remain optimal under the predicted cost. CaVE measures this alignment via a cosine loss against the cone projection \(\mathbf{p} = \mathrm{proj}_{K}(-\hat{\mathbf{c}})\),
When \(-\hat{\mathbf{c}}\) already lies inside the cone, \(\mathbf{p} = -\hat{\mathbf{c}}\) and the loss is zero; the further \(-\hat{\mathbf{c}}\) strays outside the cone, the larger the loss.
PyEPO uses Clarabel as the interior-point QP solver for the cone projection. The default max_iter=3 is the paper’s CaVE+ preset — under-converging the QP on purpose keeps the projection interior to the cone and yields a richer gradient than the exact boundary projection.
For larger problems, setting solve_ratio < 1 enables the CaVE Hybrid preset: each batch goes through the QP projection with probability solve_ratio and through a cheap heuristic (a blend of the normalized predicted cost and the average binding-constraint normal, controlled by inner_ratio) otherwise. This cuts the per-epoch QP cost without measurable regret loss in the paper’s experiments.
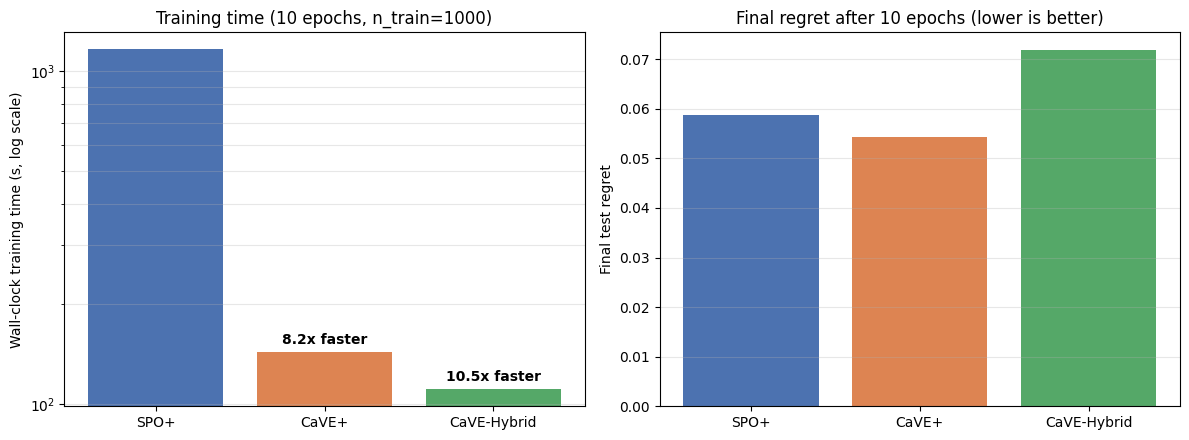
CVRP-20 head-to-head from notebook 04 (num_data=1000, 10 epochs, single-process). CaVE+ trains 8.2x faster than SPO+ at slightly lower final regret; CaVE-Hybrid (solve_ratio=0.3) is 10.5x faster, trading ~1.7 pp of regret.¶
Training data must come from pyepo.data.dataset.optDatasetConstrs, which extracts the binding-constraint normals at the optimum for each instance. Batches must be collated with pyepo.data.dataset.collate_tight_constraints to zero-pad ragged per-instance constraint counts. CaVE currently requires a Gurobi-backed optModel (binding-constraint extraction relies on Gurobi’s sparse matrix API).
- class pyepo.func.coneAlignedCosine(optmodel: optModel, max_iter: int = 3, solve_ratio: float = 1.0, inner_ratio: float = 0.2, processes: int = 1, reduction: Reduction = 'mean')
Cone-Aligned Vector Estimation (CaVE) loss for binary linear programs.
For each training instance, the sense-flipped predicted cost vector \(-\hat{\mathbf{c}}\) is projected onto the polyhedral cone spanned by the binding-constraint normals at the true optimal vertex; the loss is \(1 - \cos(-\hat{\mathbf{c}}, \mathrm{proj})\). Because the supervision is the cone of binding normals (not the optimal solution itself), CaVE side-steps the zero-gradient pathology of solver layers without requiring a perturbation or solution pool. Defined for binary linear programs only.
PyEPO uses Clarabel as the interior-point QP solver for the cone projection.
Note
The default
max_iter=3is intentional — it is the CaVE+ preset from the paper. Three IPM steps under-converge the QP on purpose so the projection stays interior to the cone, yielding a richer gradient than a fully converged boundary projection. Raisingmax_iterchanges the loss behavior.For larger problems, set
solve_ratio < 1to enable the CaVE Hybrid preset from the paper: each batch goes through the QP projection with probabilitysolve_ratioand through a cheap heuristic (normalized predicted cost blended with the average binding-constraint normal) with probability1 - solve_ratio, cutting the per-epoch cost without measurable regret loss.Training data must come from
pyepo.data.dataset.optDatasetConstrs(Gurobi-backed) and be collated withcollate_tight_constraints.Reference: Tang & Khalil (2024) https://link.springer.com/chapter/10.1007/978-3-031-60599-4_12
If you use the CaVE loss, please cite:
@inproceedings{tang2024cave,
title={CaVE: A Cone-Aligned Approach for Fast Predict-then-Optimize with Binary Linear Programs},
author={Tang, Bo and Khalil, Elias B},
booktitle={Integration of Constraint Programming, Artificial Intelligence, and Operations Research},
pages={193--210},
year={2024},
publisher={Springer}
}
Contrastive Methods¶
Contrastive methods train against a pool of cached non-optimal solutions, treated as negative examples. solve_ratio controls how often new instances are solved exactly during training; dataset seeds the pool. See Solution Pool for details on the solution-pool mechanism.
Noise Contrastive Estimation (NCE)¶
NCE [6] is a surrogate loss based on negative examples. It uses a small set of non-optimal solutions as negative samples to maximize the probability gap between the optimal solution and the rest.
Let \(\Gamma\) be the cached pool of feasible solutions. For a minimization problem, NCE averages the predicted-cost margin between \(\mathbf{w}^*(\mathbf{c})\) and every member of the pool,
(If \(\mathbf{w}^*(\mathbf{c}) \in \Gamma\), its term contributes zero and the sum effectively averages over the negatives.) The gradient has a closed form that requires no solver call in the backward pass,
For a fixed \(\Gamma\) this update direction stays constant per instance, so periodically refreshing \(\Gamma\) (controlled by solve_ratio) is essential to keep the gradient signal informative.
- class pyepo.func.noiseContrastiveEstimation(optmodel: optModel, processes: int = 1, solve_ratio: float = 1.0, reduction: Reduction = 'mean', dataset: optDataset | None = None)
Noise Contrastive Estimation (NCE) – contrastive loss against a cached solution pool.
Averages the predicted-cost margin between the true optimum and every member of the cached pool \(\Gamma\): \(\mathcal{L} = \tfrac{1}{|\Gamma|}\sum_{\mathbf{w} \in \Gamma} (\hat{\mathbf{c}}^\top \mathbf{w}^*(\mathbf{c}) - \hat{\mathbf{c}}^\top \mathbf{w})\). The gradient has a closed form (no solver call in the backward pass), so per-step cost is dominated by occasional pool refreshes rather than by solver work. Pass
solve_ratio < 1to control refresh frequency; the pool is seeded fromdatasetat construction.Reference: Mulamba et al. (2021) https://www.ijcai.org/proceedings/2021/390
Contrastive MAP (CMAP)¶
CMAP [6] is a special case of NCE that uses only the single best negative sample. It is simpler and often equally effective.
CMAP keeps only the most-violating member of the pool — the one with the smallest predicted-cost objective — yielding a max-margin contrast against the true optimum. For a minimization problem,
If \(\mathbf{w}^*(\mathbf{c}) \in \Gamma\), that entry contributes a zero margin, so the loss is non-negative and vanishes precisely when the predicted costs already make \(\mathbf{w}^*(\mathbf{c})\) the minimizer over \(\Gamma\).
- class pyepo.func.contrastiveMAP(optmodel: optModel, processes: int = 1, solve_ratio: float = 1.0, reduction: Reduction = 'mean', dataset: optDataset | None = None)
Contrastive Maximum-a-Posteriori (CMAP) – max-margin special case of NCE.
Keeps only the most-violating member of the cached pool \(\Gamma\) (the one with the smallest predicted-cost objective) as the negative: \(\mathcal{L} = \hat{\mathbf{c}}^\top \mathbf{w}^*(\mathbf{c}) - \min_{\mathbf{w} \in \Gamma} \hat{\mathbf{c}}^\top \mathbf{w}\). Simpler than NCE and often equally effective. Pool semantics (
solve_ratio,dataset) are identical to NCE.Reference: Mulamba et al. (2021) https://www.ijcai.org/proceedings/2021/390
Learning to Rank¶
Learning to rank [7] treats decision-focused learning as ranking a pool of feasible solutions: predicted costs assign scores to solutions, and the loss encourages the optimal solution to rank highest. Each variant differs in how it scores the ranking. Like contrastive methods, LTR uses solve_ratio and dataset to manage the pool.
Pointwise regresses each predicted score \(\hat{\mathbf{c}}^\top \mathbf{w}\) toward the true value \(\mathbf{c}^\top \mathbf{w}\) for every \(\mathbf{w} \in \Gamma\).
Pairwise enforces a margin: the optimal solution should rank above each suboptimal one.
Listwise models the full ranking distribution with a SoftMax over predicted scores,
\[P(\mathbf{w}' \mid \hat{\mathbf{c}}) = \frac{\exp(\hat{\mathbf{c}}^\top \mathbf{w}')}{\sum_{\mathbf{w} \in \Gamma} \exp(\hat{\mathbf{c}}^\top \mathbf{w})},\]and minimizes the cross-entropy against the true ranking distribution,
\[\mathcal{L}_{\mathrm{LTR}}^{\mathrm{list}}(\hat{\mathbf{c}}, \mathbf{c}) = -\frac{1}{|\Gamma|} \sum_{\mathbf{w} \in \Gamma} P(\mathbf{w} \mid \mathbf{c}) \log P(\mathbf{w} \mid \hat{\mathbf{c}}).\]The gradient has a closed form,
\[\frac{\partial \mathcal{L}_{\mathrm{LTR}}^{\mathrm{list}}(\hat{\mathbf{c}}, \mathbf{c})}{\partial \hat{\mathbf{c}}} = \frac{1}{|\Gamma|} \Big( \sum_{\mathbf{w} \in \Gamma} P(\mathbf{w} \mid \hat{\mathbf{c}})\, \mathbf{w} - \sum_{\mathbf{w} \in \Gamma} P(\mathbf{w} \mid \mathbf{c})\, \mathbf{w} \Big).\]
Pointwise LTR¶
Pointwise loss computes ranking scores for individual solutions.
- class pyepo.func.pointwiseLTR(optmodel: optModel, processes: int = 1, solve_ratio: float = 1.0, reduction: Reduction = 'mean', dataset: optDataset | None = None)
Pointwise Learning-to-Rank loss over a cached solution pool.
Treats each cached solution \(\mathbf{w} \in \Gamma\) as an independent regression target: the predicted score \(\hat{\mathbf{c}}^\top \mathbf{w}\) is fit toward the true score \(\mathbf{c}^\top \mathbf{w}\) via squared error, averaged over the pool. Cheapest of the three LTR variants – no cross-pool interactions. Pool semantics (
solve_ratio,dataset) are shared with the other LTR variants and with the contrastive methods.Reference: Mandi et al. (2022) https://proceedings.mlr.press/v162/mandi22a.html
Pairwise LTR¶
Pairwise loss learns the relative ordering between pairs of solutions.
- class pyepo.func.pairwiseLTR(optmodel: optModel, processes: int = 1, solve_ratio: float = 1.0, reduction: Reduction = 'mean', dataset: optDataset | None = None)
Pairwise Learning-to-Rank loss over a cached solution pool.
Enforces a margin between the true optimum (the best member of \(\Gamma\)) and each suboptimal solution via a ReLU hinge on the predicted-cost difference. Lighter than the listwise variant (no SoftMax over the full pool) and often a good first choice when the pool is large. Pool semantics (
solve_ratio,dataset) are shared with the other LTR variants and with the contrastive methods.Reference: Mandi et al. (2022) https://proceedings.mlr.press/v162/mandi22a.html
Listwise LTR¶
Listwise loss evaluates scores over the entire ranked list.
- class pyepo.func.listwiseLTR(optmodel: optModel, processes: int = 1, solve_ratio: float = 1.0, reduction: Reduction = 'mean', dataset: optDataset | None = None)
Listwise Learning-to-Rank loss over a cached solution pool.
Models the ranking distribution over the cached pool \(\Gamma\) as SoftMax of predicted-cost scores and minimizes its cross-entropy against the true ranking distribution. The full-list formulation captures interactions between every pair of solutions in \(\Gamma\). Pool semantics (
solve_ratio,dataset) are shared with the other LTR variants and with the contrastive methods.Reference: Mandi et al. (2022) https://proceedings.mlr.press/v162/mandi22a.html
Parallel Computation¶
All pyepo.func modules support parallel solving during training via the processes parameter (0 uses all available cores).
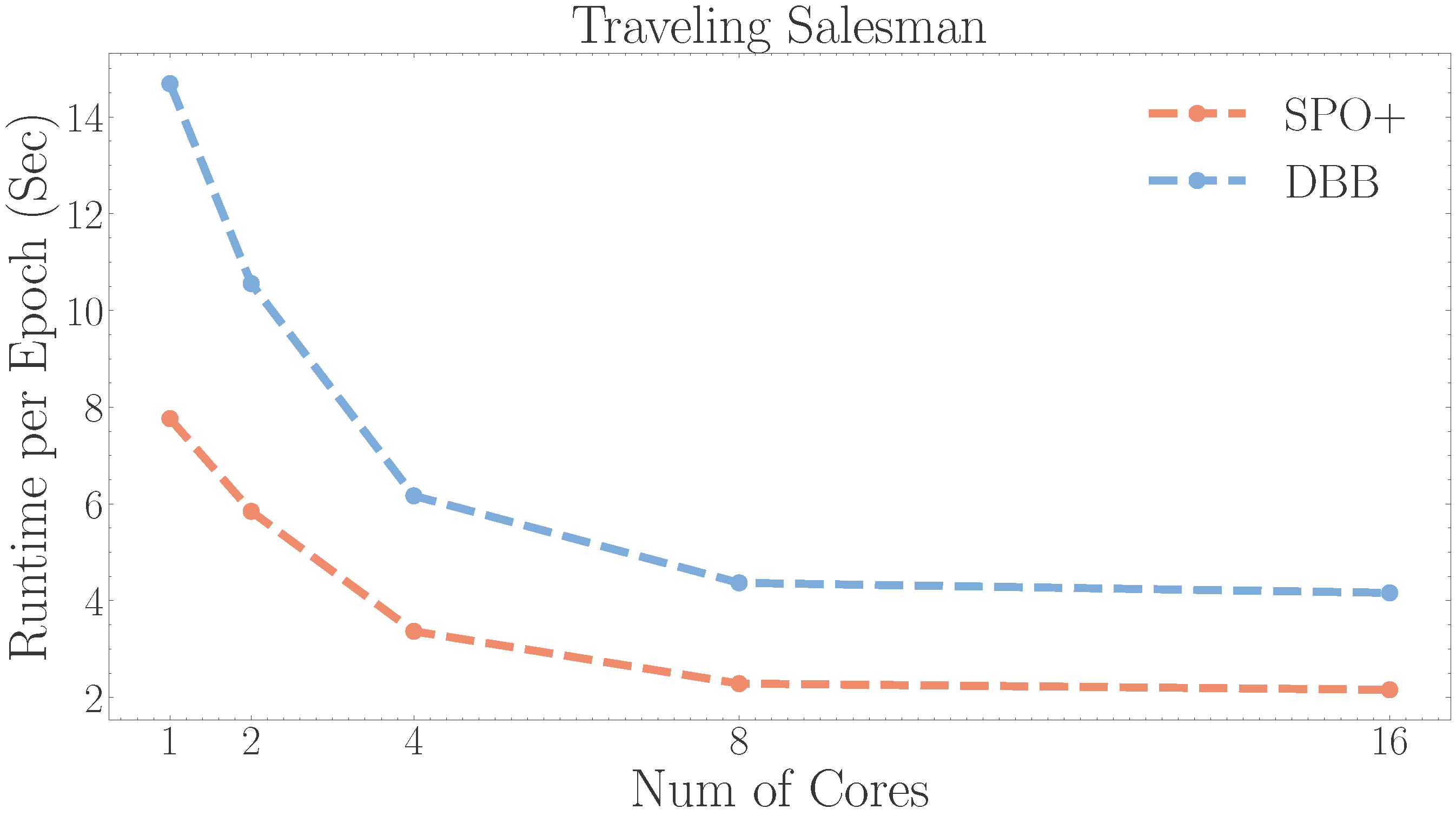
The figure shows that increasing the number of processes reduces runtime.
Footnotes